TL;DR: We propose a text-to-image model that precisely controls the amount and location of defocus blur in generated images while preserving the scene content.


Abstract
Current text-to-image diffusion models excel at generating diverse, high-quality images, yet they struggle to incorporate fine-grained camera metadata such as precise aperture settings. In this work, we introduce a novel text-to-image diffusion framework that leverages camera metadata, or EXIF data, which is often embedded in image files, with an emphasis on generating controllable lens blur. Our method mimics the physical image formation process by first generating an all-in-focus image, estimating its monocular depth, predicting a plausible focus distance with a novel focus distance transformer, and then forming a defocused image with an existing differentiable lens blur model2. Gradients flow backwards through this whole process, allowing us to learn without explicit supervision to generate defocus effects based on content elements and the provided EXIF data. At inference time, this enables precise interactive user control over defocus effects while preserving scene contents, which is not achievable with existing diffusion models. Experimental results demonstrate that our model enables superior fine-grained control without altering the depicted scene.
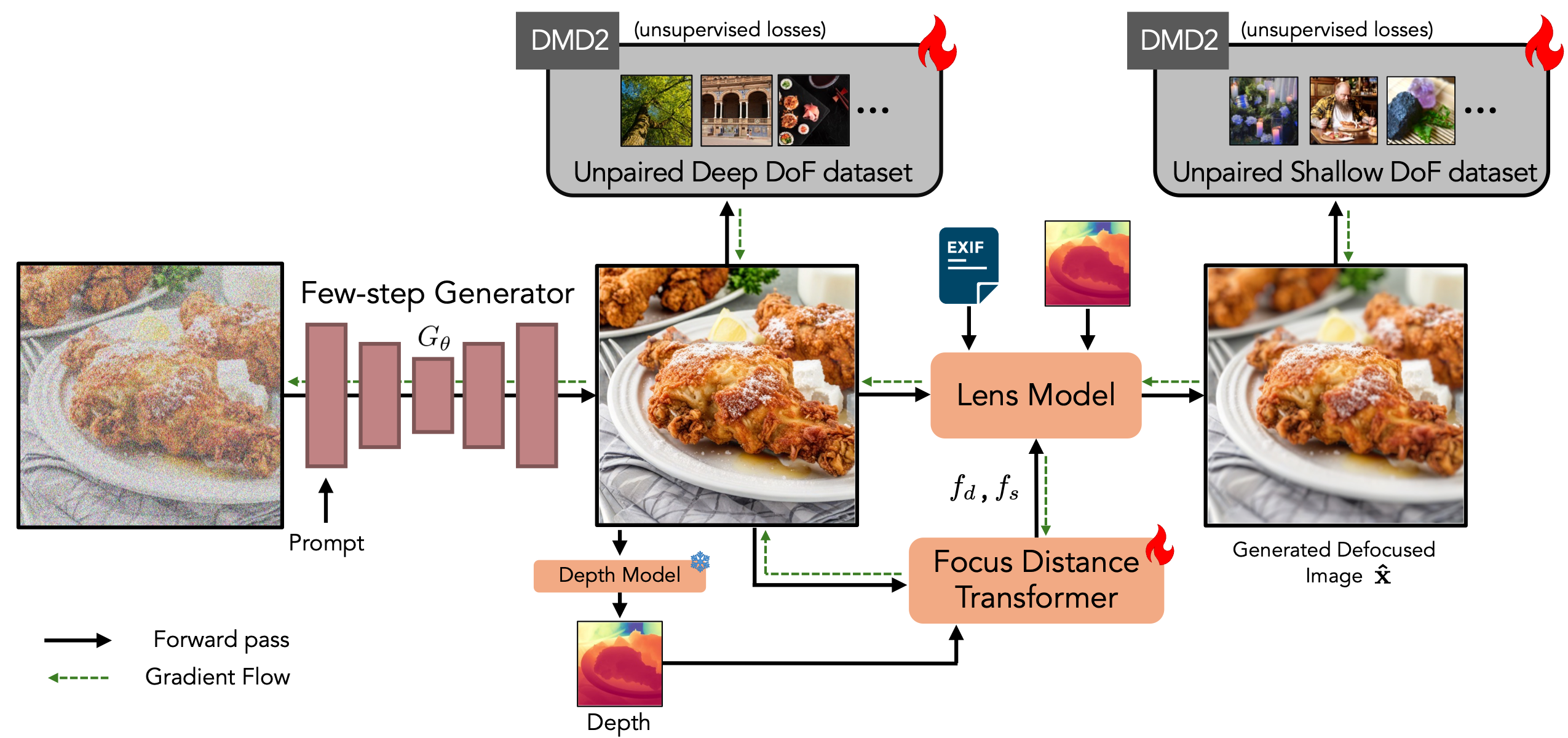
Our model obtains its supervision from a differentiable lens model and training examples of images with shallow and deep depth-of-field. We train our model to generate an all-in-focus image using $G_{\theta}$. A depth model then predicts depth for this image, which, along with the image itself, is fed into a model that estimates the focus distance $f_d$ and depth scale $f_s$. Finally, a lens model combines EXIF data with these predictions to apply spatially varying blur, generating the final image. We train the all-in-focus generator using unsupervised DMD23 losses on our unpaired Deep DoF dataset and optimize the entire pipeline with DMD2 losses on the unpaired Shallow DoF dataset.
Results
Comparisons with SDXL + Dr.Bokeh



Comparisons with Camera Settings as Tokens


Comparison with EBB! Dataset
Drag the slider on the images to compare all-in-focus and defocused images.
Aperture: f/1.8
Generated image
Aperture: f/16


Aperture: f/1.8
Generated image
Aperture: f/16


Prompt: A red and gray fire hydrant is positioned next to a dense green hedge along a sidewalk. The hydrant has a red cap. The surrounding area includes a concrete curb and scattered leaves on the pavement.
Prompt: Vibrant pink rose blooming in a lush garden, surrounded by green foliage and a rustic wooden fence.
Aperture: f/1.8
EBB! dataset image
Aperture: f/16


Aperture: f/1.8
EBB! dataset image
Aperture: f/16


Aperture: f/1.8
Generated image
Aperture: f/16


Aperture: f/1.8
Generated image
Aperture: f/16


Prompt: Urban graffiti on a concrete block near a road, with greenery sprouting around its base.
Prompt: A green wheeled trash bin is placed on the street in front of a house with a brown wooden door and a gray and brown picket fence. The house has a peach-colored exterior with white window shutters. Another gray trash bin is partially visible behind the fence.
Aperture: f/1.8
EBB! dataset image
Aperture: f/16

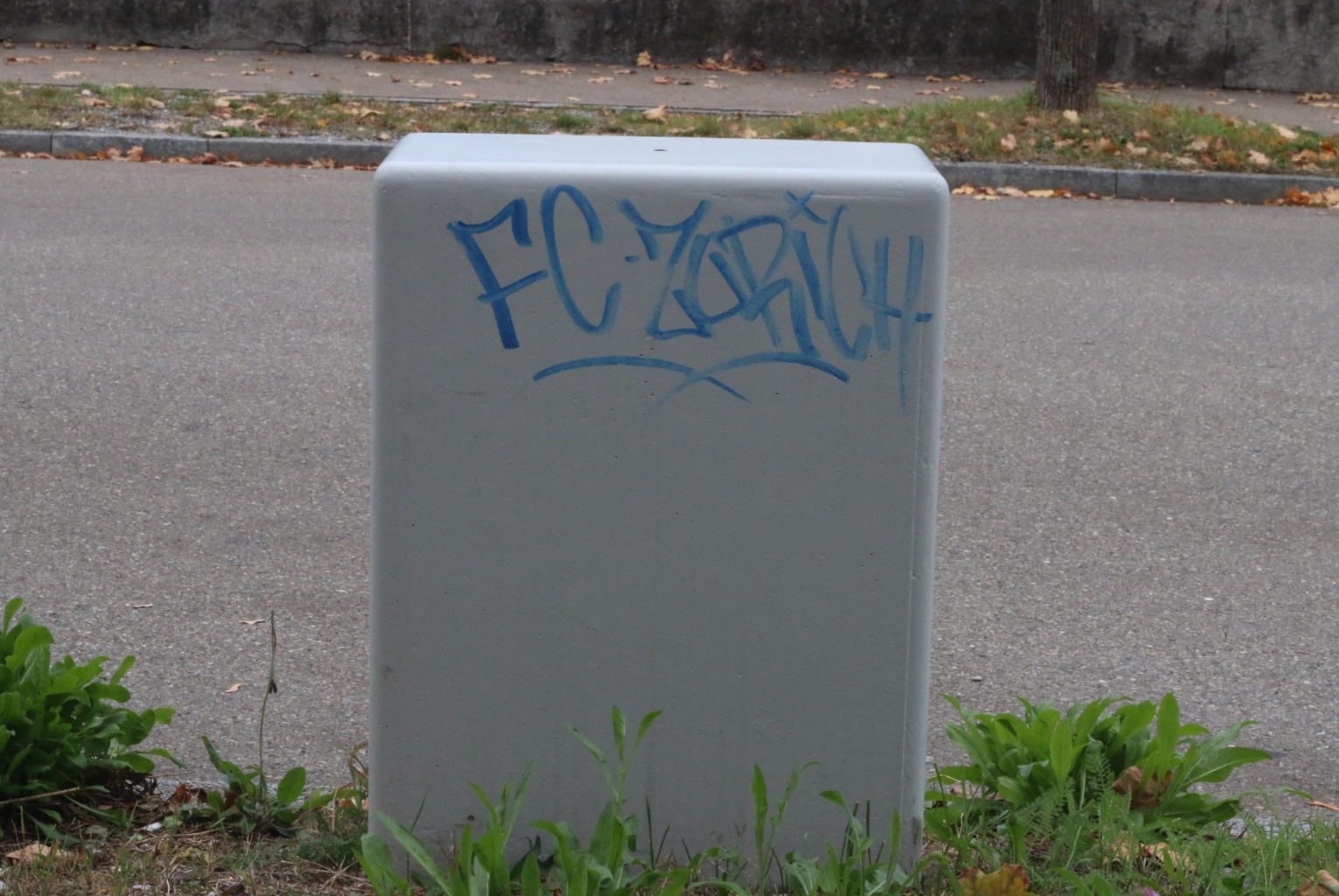
Aperture: f/1.8
EBB! dataset image
Aperture: f/16


Aperture: f/1.8
Generated image
Aperture: f/16


Aperture: f/1.8
Generated image
Aperture: f/16


Prompt: A weathered stone sphere with patches of moss, set against a backdrop of autumn foliage and a modern building.
Prompt: A gray Nissan Juke parked on a residential street with a hedge and house in the background.
Aperture: f/1.8
EBB! dataset image
Aperture: f/16


Aperture: f/1.8
EBB! dataset image
Aperture: f/16


Aperture: f/1.8
Generated image
Aperture: f/16


Aperture: f/1.8
Generated image
Aperture: f/16


Prompt: Red and white bollard next to a tree with fallen autumn leaves on the ground.
Prompt: A weathered stone lantern, standing tall amidst the vibrant autumn foliage.
Aperture: f/1.8
EBB! dataset image
Aperture: f/16


Aperture: f/1.8
EBB! dataset image
Aperture: f/16


Aperture: f/1.8
Generated image
Aperture: f/16


Aperture: f/1.8
Generated image
Aperture: f/16


Prompt: A yellow pole stands in a park surrounded by trees and greenery.
Prompt: A fire hydrant with the number 674 on it stands in a wooded area with trees and bushes in the background.
Aperture: f/1.8
EBB! dataset image
Aperture: f/16


Aperture: f/1.8
EBB! dataset image
Aperture: f/16

