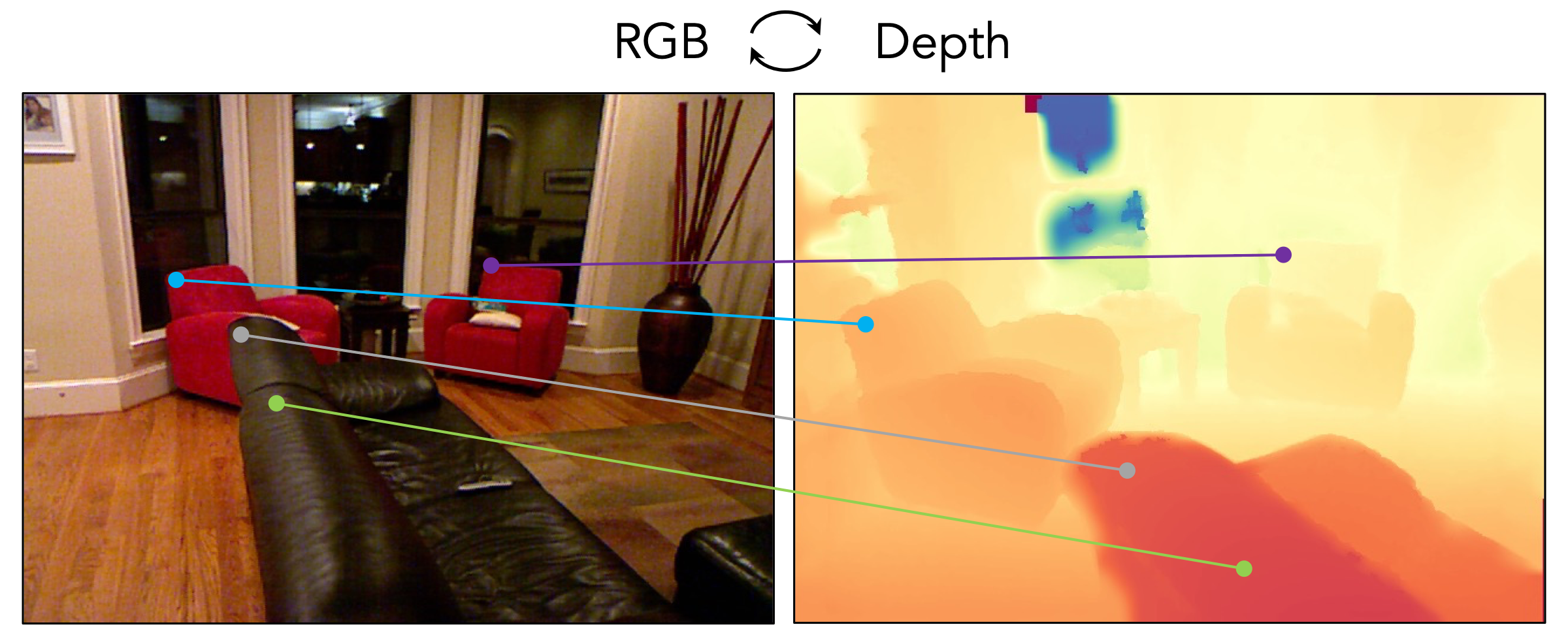
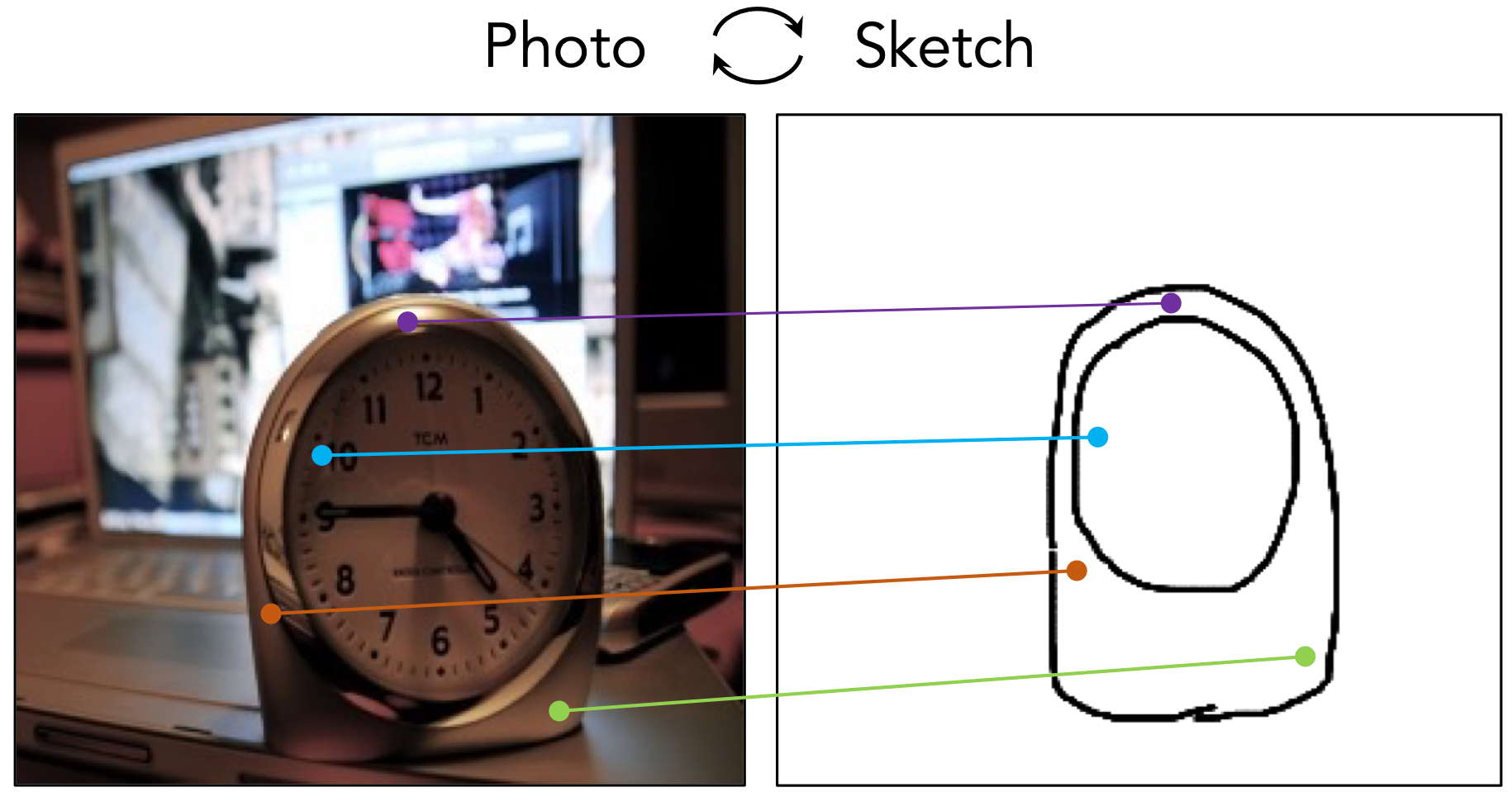
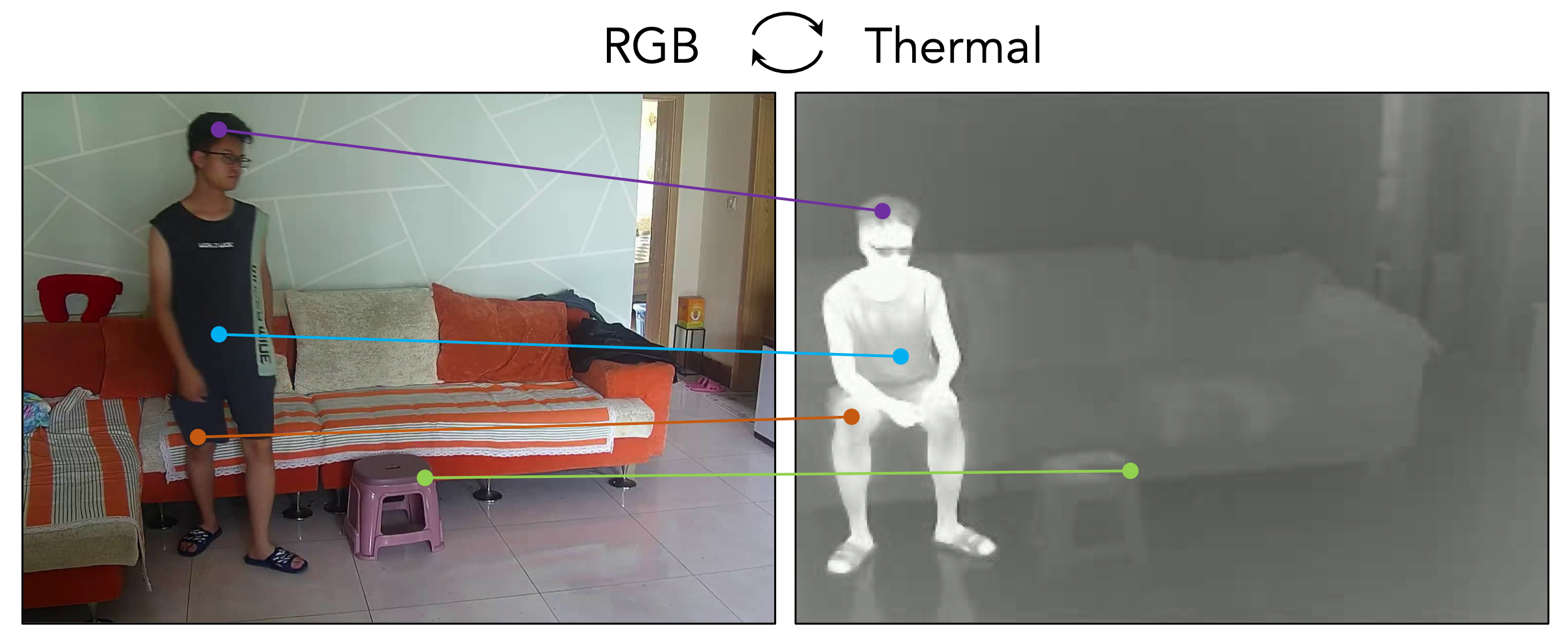

Geometric Correspondence
Semantic Correspondence
We present a method for finding cross-modal space-time correspondences. Given two images from different visual modalities, such as an RGB image and a depth map, our model identifies which pairs of pixels correspond to the same physical points in the scene. To solve this problem, we extend the contrastive random walk framework to simultaneously learn cycle-consistent feature representations for both cross-modal and intra-modal matching. The resulting model is simple and has no explicit photo-consistency assumptions. It can be trained entirely using unlabeled data, without the need for any spatially aligned multimodal image pairs. We evaluate our method on both geometric and semantic correspondence tasks. For geometric matching, we consider challenging tasks such as RGB-to-depth and RGB-to-thermal matching (and vice versa); for semantic matching, we evaluate on photo-sketch and cross-style image alignment. Our method achieves strong performance across all benchmarks.
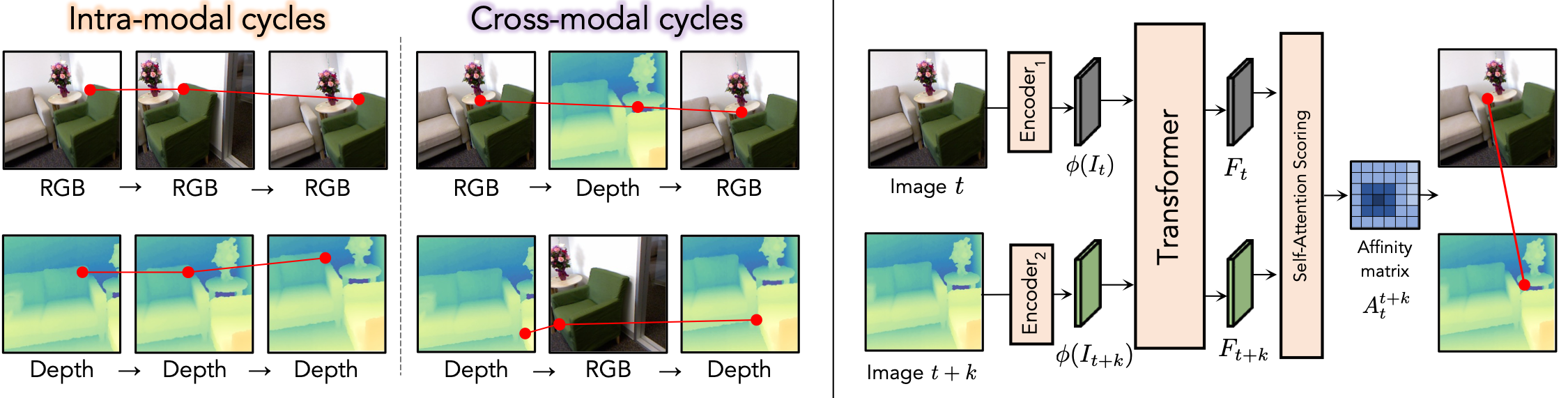
We learn to find pixel-level correspondences between images that may differ in sensory modality, time, and scene position. Given images from two modalities (e.g., unpaired RGB and depth images from the same scene), we perform a contrastive random walk on a graph whose nodes come from patches within the two images using a global matching transformer architecture1. We simultaneously perform auxiliary intra-modal random walks within each modality's augmented crops of images to improve the model's ability to avoid local minima during optimization. Through this process, we learn to match in both directions (e.g., RGB-to-depth and depth-to-RGB).
Given a text prompt, we generate images in various styles using a text-to-image model. Each image is conditioned on a base prompt combined with a style modifier. Our model is then used to find correspondences between the generated images.
@InProceedings{shrivastava2025cmrw,
title = {Self-Supervised Spatial Correspondence Across Modalities},
author = {Shrivastava, Ayush and Owens, Andrew},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2025},
url = {https://arxiv.org/abs/2506.03148},
}